- 【python×sklearn】による非線形SVMの実装方法
- メッシュグリッドによるハイパーパラメータ(C,gamma)の調整
- 境界線の描画
- 学習したモデルを使った未知データに対する推論と結果表示
本記事では、非線形SVMによる2クラス分類について、最適なハイパーパラメータ(C,gamma)を調整しながらわかりやすく結果表示していきます。
非線形SVM
学習データ
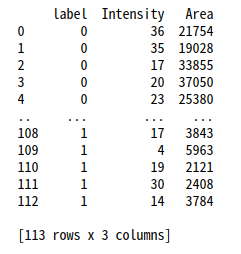
以下のようなデータ’train_data.csv’に対して、SVMによる2クラスの分類モデルを作成します。
# CSVファイル名
input_csv_filename = 'train_data.csv'
# データフレームを作成
df = pd.read_csv(input_csv_filename, names=['label', 'Intensity', 'Area'])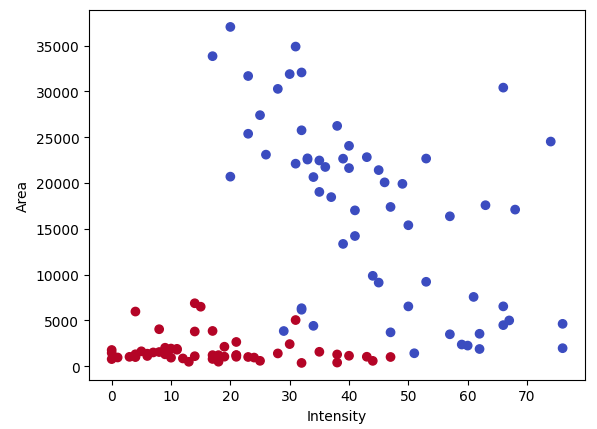
パラメータの調整
まずは、適切なCとgamma値を探します。
学習の際、SVMのようなマージンベースのアルゴリズムでは、特徴量のスケーリングが重要です。
sklearnのStandardScalerによってスケーリングしてから行います。
# 特徴量のスケーリング
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)<適切なパラメータを確認するための実行コード>
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm
import pandas as pd
from sklearn.preprocessing import StandardScaler
# CSVファイル名
input_csv_filename = 'train_data.csv'
# データフレームを作成
df = pd.read_csv(input_csv_filename, names=['label', 'Intensity', 'Area'])
# データを取得
y = df['label']
X = df[['Intensity', 'Area']]
# 特徴量のスケーリング
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# Cとgammaのリストを定義
C_values = [0.1, 1, 10]
gamma_values = [0.1, 1, 10]
# グラフのサイズを設定
plt.figure(figsize=(15, 12))
# Cとgammaの各組み合わせでモデルをトレーニングし、結果をプロット
for i, C in enumerate(C_values):
for j, gamma in enumerate(gamma_values):
model = svm.SVC(kernel='rbf', C=C, gamma=gamma) # 'rbf'カーネルを使用してCとgammaをセット
model.fit(X_scaled, y)
# 分類境界をプロット
x_min, x_max = X['Intensity'].min() - 1, X['Intensity'].max() + 2
y_min, y_max = X['Area'].min() - 1000, X['Area'].max() + 1000
xx, yy = np.meshgrid(np.arange(x_min, x_max, 1), np.arange(y_min, y_max, 1))
# メッシュグリッドをスケーリング
xx_scaled = scaler.transform(np.c_[xx.ravel(), yy.ravel()])[:, 0].reshape(xx.shape)
yy_scaled = scaler.transform(np.c_[xx.ravel(), yy.ravel()])[:, 1].reshape(yy.shape)
# スケーリングしたメッシュグリッドで予測
Z = model.predict(np.c_[xx_scaled.ravel(), yy_scaled.ravel()])
Z = Z.reshape(xx.shape)
# サブプロットを作成
plt.subplot(len(C_values), len(gamma_values), i * len(gamma_values) + j + 1)
plt.contourf(xx, yy, Z, alpha=0.2, cmap=plt.cm.coolwarm)
plt.scatter(X['Intensity'], X['Area'], c=y, cmap=plt.cm.coolwarm)
plt.title(f'C={C}, gamma={gamma}')
# グラフを表示
plt.tight_layout()
plt.show()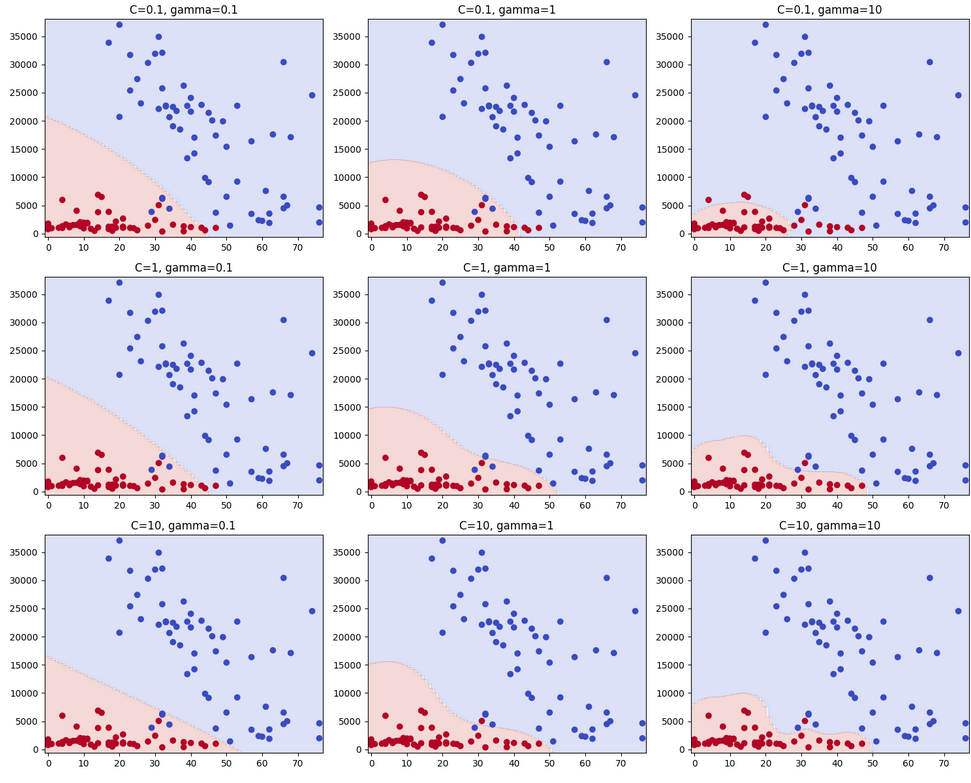
グラフの軸はデータセットに合わせて下の部分を調整してください。
# 分類境界をプロット
x_min, x_max = X['Intensity'].min() - 1, X['Intensity'].max() + 2
y_min, y_max = X['Area'].min() - 1000, X['Area'].max() + 1000各パラメータでの学習結果が表示することができました。
今回はC=10, gamma=1で進めます。
一般的に、学習時のSVMのハイパーパラメータは主に以下のものを変更する場合が多いです。
今回は非線形で分類したかったので、カーネルは’rbf’を選択しています。
- C: 正則化パラメータ
値が小さいほど決定境界はスムーズ
大きいと各データポイントの分類の正確さが増す - kernel: 使用するカーネルのタイプ
’linear’: 線形カーネル
’poly’: 多項式カーネル
’rbf’: Radial basis function(放射基底関数)カーネル
’sigmoid’: シグモイドカーネル - gamma(カーネルが’rbf’, ‘poly’, ‘sigmoid’の場合)
サンプルが影響を持つ範囲を定義
値が小さい場合は広い範囲、大きい場合は狭い範囲
学習と結果表示
次に、決めたパラメータで再度学習してモデルを作ります。
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm
import pandas as pd
from sklearn.preprocessing import StandardScaler
# CSVファイル名
input_csv_filename = 'train_data.csv'
# データフレームを作成
df = pd.read_csv(input_csv_filename, names=['label', 'Intensity', 'Area'])
# データを取得
y = df['label']
X = df[['Intensity', 'Area']]
# 特徴量のスケーリング
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 非線形SVMモデルを設定(rbfカーネルを使用)
model = svm.SVC(kernel='rbf', C=10, gamma=1)
# モデルをトレーニング
model.fit(X_scaled, y)
# 分類境界をプロット
x_min, x_max = X['Intensity'].min() - 1, X['Intensity'].max() + 2
y_min, y_max = X['Area'].min() - 1000, X['Area'].max() + 1000
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.5), np.arange(y_min, y_max, 0.5))
# メッシュグリッドをスケーリング
xx_scaled = scaler.transform(np.c_[xx.ravel(), yy.ravel()])[:, 0].reshape(xx.shape)
yy_scaled = scaler.transform(np.c_[xx.ravel(), yy.ravel()])[:, 1].reshape(yy.shape)
# スケーリングしたメッシュグリッドで予測
Z = model.predict(np.c_[xx_scaled.ravel(), yy_scaled.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, alpha=0.2, cmap=plt.cm.coolwarm)
plt.scatter(X['Intensity'], X['Area'], c=y, cmap=plt.cm.coolwarm)
# 軸ラベルとタイトル
plt.xlabel('Intensity')
plt.ylabel('Area')
plt.title('SVM Decision Boundary')
# グラフをファイルとして保存
plt.savefig('svm_results.png', dpi=300)
plt.show()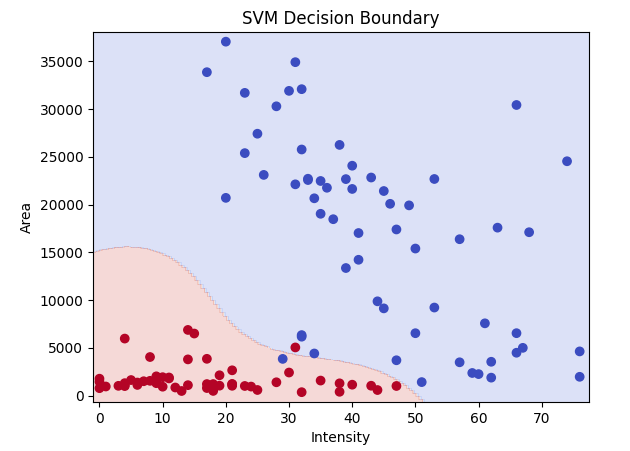
学習したモデルでの推論と結果出力
続いて、学習したモデルに以下のような新たなデータ’test_data.csv’を与えて結果を出力してみます。
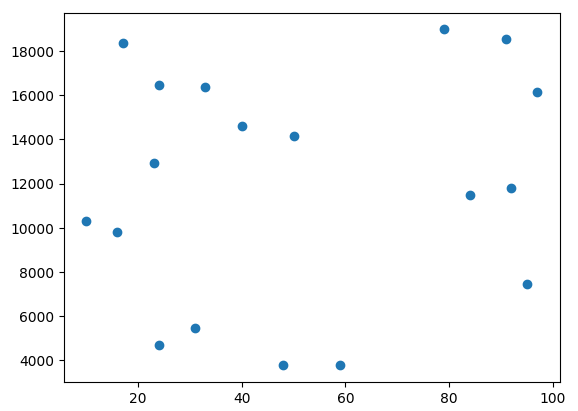

<推論するコードと結果>
# 新たなCSVファイル名
input_new_csv_filename = 'test_data.csv'
output_csv_filename = 'prediction_results.csv'
# 新たなデータフレームを作成
new_df = pd.read_csv(input_new_csv_filename, names=['Intensity', 'Area'])
# 新たなデータをスケーリング
new_X_scaled = scaler.transform(new_df)
# トレーニングしたモデルで新たなデータを推論
predictions = model.predict(new_X_scaled)
# 結果を新たなデータフレームに追加
new_df['Predicted_Label'] = predictions
# 結果をCSVファイルに出力
new_df.to_csv(output_csv_filename, index=False)
print(new_df)
# xx, yyの範囲を全データの範囲に基づいて更新
combined_df = pd.concat([df[['Intensity', 'Area']], new_df[['Intensity', 'Area']]])
x_min, x_max = combined_df['Intensity'].min() - 1, combined_df['Intensity'].max() + 2
y_min, y_max = combined_df['Area'].min() - 1000, combined_df['Area'].max() + 1000
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.5), np.arange(y_min, y_max, 0.5))
# メッシュグリッドをスケーリング
xx_scaled = scaler.transform(np.c_[xx.ravel(), yy.ravel()])[:, 0].reshape(xx.shape)
yy_scaled = scaler.transform(np.c_[xx.ravel(), yy.ravel()])[:, 1].reshape(yy.shape)
# スケーリングしたメッシュグリッドで予測
Z = model.predict(np.c_[xx_scaled.ravel(), yy_scaled.ravel()])
Z = Z.reshape(xx.shape)
# 推論結果をプロット
plt.contourf(xx, yy, Z, alpha=0.2, cmap=plt.cm.coolwarm)
plt.scatter(new_df['Intensity'], new_df['Area'], c=new_df['Predicted_Label'], cmap=plt.cm.coolwarm, edgecolors='k')
# 軸ラベルとタイトル
plt.xlabel('Intensity')
plt.ylabel('Area')
plt.title('SVM Prediction Results')
# グラフをファイルとして保存
plt.savefig('SVM_prediction_results.png', dpi=300)
plt.show()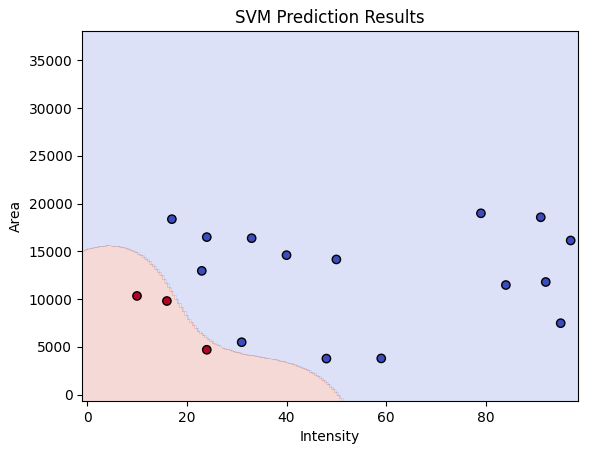
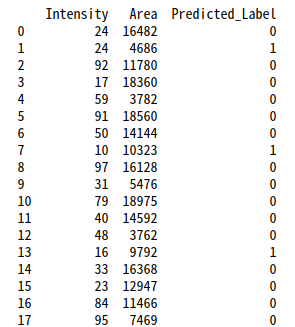
しっかり分類できたことが確認できました。

