- 【python×sklearn】によるロジステック回帰モデルの実装方法
- 分類境界線のプロットと境界式の出力
- 学習済みモデルを使った新規データの推論結果確認
この記事では、ロジスティック回帰による2クラス分類を行い、その結果をわかりやすく出力します。
ロジステック回帰
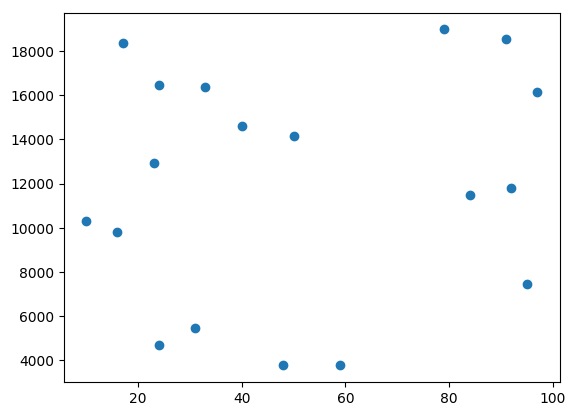
学習データ
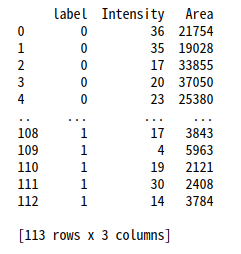
以下のようなデータが含まれる’train_data.csv’に対して、ロジステック回帰による2クラスの分類モデルを作成します。
# CSVファイル名
input_csv_filename = 'train_data.csv'
# データフレームを作成
df = pd.read_csv(input_csv_filename, names=['label', 'Intensity', 'Area'])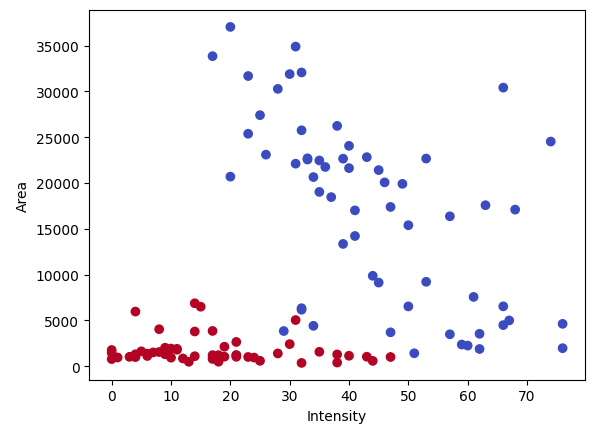
モデルの学習と分類境界表示
まずはロジステック回帰モデルの学習と結果を見てみます。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression
import pandas as pd
# CSVファイル名
input_csv_filename = 'train_data.csv'
# データフレームを作成
df = pd.read_csv(input_csv_filename, names=['label', 'Intensity', 'Area'])
# データを取得
y = df['label']
X = df[['Intensity', 'Area']]
# ロジスティック回帰モデルを設定
model = LogisticRegression()
# モデルをトレーニング
model.fit(X, y)
# 分類境界をプロット
x_min, x_max = X['Intensity'].min() - 1, X['Intensity'].max() + 2
y_min, y_max = X['Area'].min() - 1000, X['Area'].max() + 1000
xx, yy = np.meshgrid(np.arange(x_min, x_max, 1), np.arange(y_min, y_max, 1))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, alpha=0.2, cmap=plt.cm.coolwarm)
plt.scatter(X['Intensity'], X['Area'], c=y, cmap=plt.cm.coolwarm)
# 軸ラベルとタイトル
plt.xlabel('Intensity')
plt.ylabel('Area')
plt.title('Logistic Regression Decision Boundary')
# グラフをファイルとして保存
plt.savefig('logistic_regression_results.png', dpi=300)
plt.show()グラフの軸はデータセットに合わせて下の部分を調整してください。
# 分類境界をプロット
x_min, x_max = X['Intensity'].min() - 1, X['Intensity'].max() + 2
y_min, y_max = X['Area'].min() - 1000, X['Area'].max() + 1000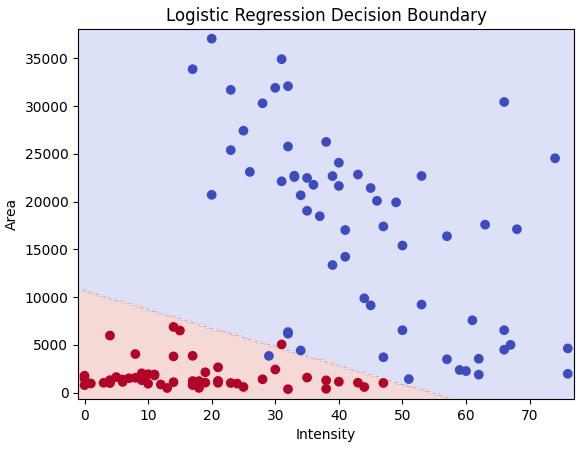
誤分類の少ないところに直線の境界線を引くことができています。
境界線の式を表示
次に決定境界の式を出力してみます。
# ロジスティック回帰モデルから重みベクトルとバイアスを取得
w = model.coef_[0]
b = model.intercept_[0]
# 境界線の式を表示
digits = 4 #表示する有効数字
print(f'境界線の式: {w[0]:.{digits}g}*Intensity + {w[1]:.{digits}g}*Area + {b:.{digits}g} = 0')境界線の式: -0.3481*Intensity + -0.001779*Area + 18.95 = 0
この式が0を超えるときにクラス=0、0未満のときにクラス=1となります。
学習したモデルでテストデータの推論
続いて、学習したモデルに以下のような新たなデータ’test_data.csv’を与えて結果を出力してみます。

<推論するコードと結果>
# 新たなCSVファイル名
input_new_csv_filename = 'test_data.csv'
output_csv_filename = 'prediction_results.csv'
# 新たなデータフレームを作成
new_df = pd.read_csv(input_new_csv_filename, names=['Intensity', 'Area'])
# 新たなデータから推論を行う
predictions = model.predict(new_df)
# 結果を新たなデータフレームに追加
new_df['Predicted_Label'] = predictions
# 結果をCSVファイルに出力
new_df.to_csv(output_csv_filename, index=False)
print(new_df)
# xx, yyの範囲を全データの範囲に基づいて更新
combined_df = pd.concat([df[['Intensity', 'Area']], new_df[['Intensity', 'Area']]])
x_min, x_max = combined_df['Intensity'].min() - 1, combined_df['Intensity'].max() + 2
y_min, y_max = combined_df['Area'].min() - 1000, combined_df['Area'].max() + 1000
xx, yy = np.meshgrid(np.arange(x_min, x_max, 1), np.arange(y_min, y_max, 1))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# 推論結果をプロット
plt.contourf(xx, yy, Z, alpha=0.2, cmap=plt.cm.coolwarm)
plt.scatter(new_df['Intensity'], new_df['Area'], c=new_df['Predicted_Label'], cmap=plt.cm.coolwarm, edgecolors='k')
# 軸ラベルとタイトル
plt.xlabel('Intensity')
plt.ylabel('Area')
plt.title('Logistic Regression Prediction Results')
# グラフをファイルとして保存
plt.savefig('logistic_regression_prediction_results.png', dpi=300)
plt.show()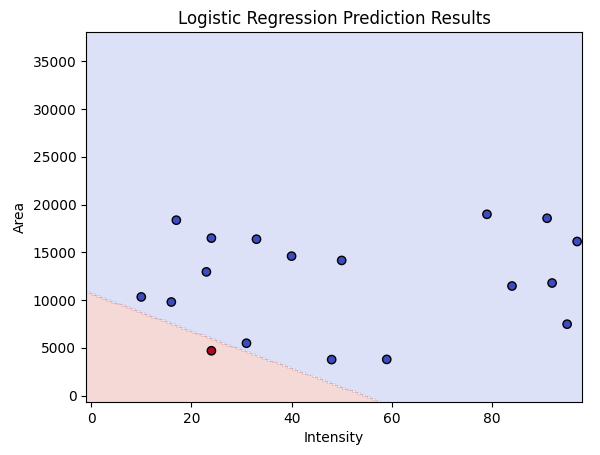
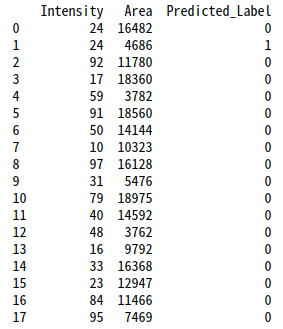
未知のデータに対してしっかり分類できていることが確認できました。
最後に全体のコードを載せておきます。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression
import pandas as pd
# CSVファイル名
input_csv_filename = 'train_data.csv'
# データフレームを作成
df = pd.read_csv(input_csv_filename, names=['label', 'Intensity', 'Area'])
# データを取得
y = df['label']
X = df[['Intensity', 'Area']]
# ロジスティック回帰モデルを設定
model = LogisticRegression()
# モデルをトレーニング
model.fit(X, y)
# 分類境界をプロット
x_min, x_max = X['Intensity'].min() - 1, X['Intensity'].max() + 2
y_min, y_max = X['Area'].min() - 1000, X['Area'].max() + 1000
xx, yy = np.meshgrid(np.arange(x_min, x_max, 1), np.arange(y_min, y_max, 1))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, alpha=0.2, cmap=plt.cm.coolwarm)
plt.scatter(X['Intensity'], X['Area'], c=y, cmap=plt.cm.coolwarm)
# 軸ラベルとタイトル
plt.xlabel('Intensity')
plt.ylabel('Area')
plt.title('Logistic Regression Decision Boundary')
# グラフをファイルとして保存
plt.savefig('logistic_regression_results.png', dpi=300)
plt.show()
# ================= 決定境界の表示 ===================
# ロジスティック回帰モデルから重みベクトルとバイアスを取得
w = model.coef_[0]
b = model.intercept_[0]
# 境界線の式を表示
digits = 4 #表示する有効数字
print(f'境界線の式: {w[0]:.{digits}g}*Intensity + {w[1]:.{digits}g}*Area + {b:.{digits}g} = 0')
# ================= 推論と結果出力===================
# 新たなCSVファイル名
input_new_csv_filename = 'test_data.csv'
output_csv_filename = 'prediction_results.csv'
# 新たなデータフレームを作成
new_df = pd.read_csv(input_new_csv_filename, names=['Intensity', 'Area'])
# 新たなデータから推論を行う
predictions = model.predict(new_df)
# 結果を新たなデータフレームに追加
new_df['Predicted_Label'] = predictions
# 結果をCSVファイルに出力
new_df.to_csv(output_csv_filename, index=False)
print(new_df)
# xx, yyの範囲を全データの範囲に基づいて更新
combined_df = pd.concat([df[['Intensity', 'Area']], new_df[['Intensity', 'Area']]])
x_min, x_max = combined_df['Intensity'].min() - 1, combined_df['Intensity'].max() + 2
y_min, y_max = combined_df['Area'].min() - 1000, combined_df['Area'].max() + 1000
xx, yy = np.meshgrid(np.arange(x_min, x_max, 1), np.arange(y_min, y_max, 1))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# 推論結果をプロット
plt.contourf(xx, yy, Z, alpha=0.2, cmap=plt.cm.coolwarm)
plt.scatter(new_df['Intensity'], new_df['Area'], c=new_df['Predicted_Label'], cmap=plt.cm.coolwarm, edgecolors='k')
# 軸ラベルとタイトル
plt.xlabel('Intensity')
plt.ylabel('Area')
plt.title('Logistic Regression Prediction Results')
# グラフをファイルとして保存
plt.savefig('logistic_regression_prediction_results.png', dpi=300)
plt.show()
