- 【python×sklearn】による線形SVMの実装方法
- 境界線のグラフ表示と境界式の確認
- 学習モデルを使った未知データに対する推論と結果表示
本記事では、線型SVMによる2クラス分類の実施とその分類結果についてわかりやすく表示します。
線形SVM
学習データ
以下のようなデータ’train_data.csv’に対して、線型SVMによる2クラスの分類モデルを作成します。
# CSVファイル名
input_csv_filename = 'train_data.csv'
# データフレームを作成
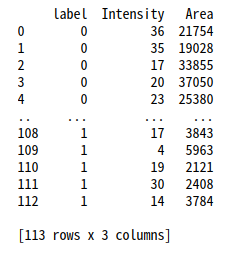
df = pd.read_csv(input_csv_filename, names=['label', 'Intensity', 'Area'])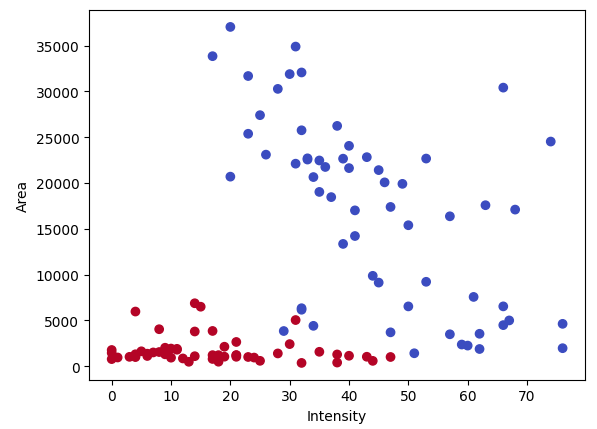
モデルの学習と分類境界のプロット
まずは線型SVMモデルの学習と結果を見てみます。
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm
import pandas as pd
# CSVファイル名
input_csv_filename = 'train_data.csv'
# データフレームを作成
df = pd.read_csv(input_csv_filename, names=['label', 'Intensity', 'Area'])
# データを取得
y = df['label']
X = df[['Intensity', 'Area']]
# 非線形SVMモデルを設定(linearカーネルを使用)
model = svm.SVC(kernel='linear', C=1)
# モデルをトレーニング
model.fit(X, y)
# 分類境界をプロット
x_min, x_max = X['Intensity'].min() - 1, X['Intensity'].max() + 2
y_min, y_max = X['Area'].min() - 1000, X['Area'].max() + 1000
xx, yy = np.meshgrid(np.arange(x_min, x_max, 1), np.arange(y_min, y_max, 1))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, alpha=0.2, cmap=plt.cm.coolwarm)
plt.scatter(X['Intensity'], X['Area'], c=y, cmap=plt.cm.coolwarm)
# サポートベクトルを描画
plt.scatter(model.support_vectors_[:, 0], model.support_vectors_[:, 1], s=100, facecolors='none', edgecolors='k')
# 軸ラベルとタイトル
plt.xlabel('Intensity')
plt.ylabel('Area')
plt.title('SVM Decision Boundary')
# グラフをファイルとして保存
plt.savefig('svm_results.png', dpi=300)
plt.show()グラフの軸はデータセットに合わせて下の部分を調整してください。
# 分類境界をプロット
x_min, x_max = X['Intensity'].min() - 1, X['Intensity'].max() + 2
y_min, y_max = X['Area'].min() - 1000, X['Area'].max() + 1000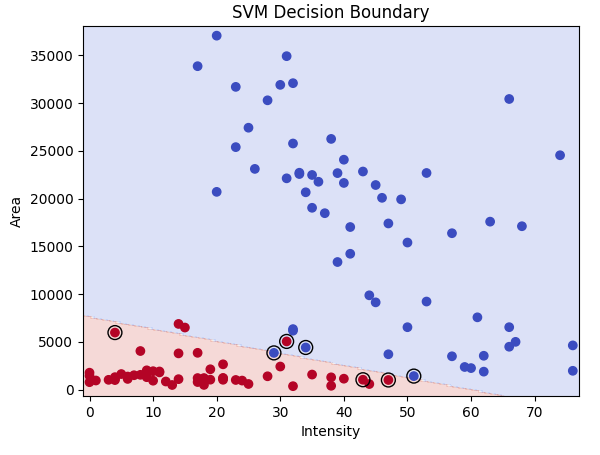
黒枠で囲まれた点はサポートベクトルを表しています。
学習時のSVMのハイパーパラメータは主に以下のものを変更する場合が多いです。
今回は線形で分類したかったので、カーネルは’linear’を選択しています。
- C: 正則化パラメータ
値が小さいほど決定境界はスムーズ
大きいと各データポイントの分類の正確さが増す - kernel: 使用するカーネルのタイプ
’linear’: 線形カーネル
’poly’: 多項式カーネル
’rbf’: Radial basis function(放射基底関数)カーネル
’sigmoid’: シグモイドカーネル - gamma(カーネルが’rbf’, ‘poly’, ‘sigmoid’の場合)
サンプルが影響を持つ範囲を定義
値が小さい場合は広い範囲、大きい場合は狭い範囲
ちなみに、C値を可変して結果を見たい場合は以下のコードで確認できます。
C_values に確認したい値をリストで記載してください。
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm
import pandas as pd
# CSVファイル名
input_csv_filename = 'train_data.csv'
# データフレームを作成
df = pd.read_csv(input_csv_filename, names=['label', 'Intensity', 'Area'])
# データを取得
y = df['label']
X = df[['Intensity', 'Area']]
# Cのリストを定義
C_values = [0.1, 1, 10,100]
# グラフのサイズを設定
plt.figure(figsize=(8, 6))
# Cとgammaの各組み合わせでモデルをトレーニングし、結果をプロット
for i, C in enumerate(C_values):
model = svm.SVC(kernel='linear', C=C) # 'linear'カーネルを使用してCとgammaをセット
model.fit(X, y)
# 予測値を計算
xx, yy = np.meshgrid(np.arange(x_min, x_max, 1), np.arange(y_min, y_max, 1))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# サブプロットを作成
plt.subplot(2, 2, i+1) # 2x2のサブプロットの位置を指定
plt.contourf(xx, yy, Z, alpha=0.2, cmap=plt.cm.coolwarm)
plt.scatter(X['Intensity'], X['Area'], c=y, cmap=plt.cm.coolwarm)
plt.title(f'C={C}')
# グラフを表示
plt.tight_layout()
plt.show()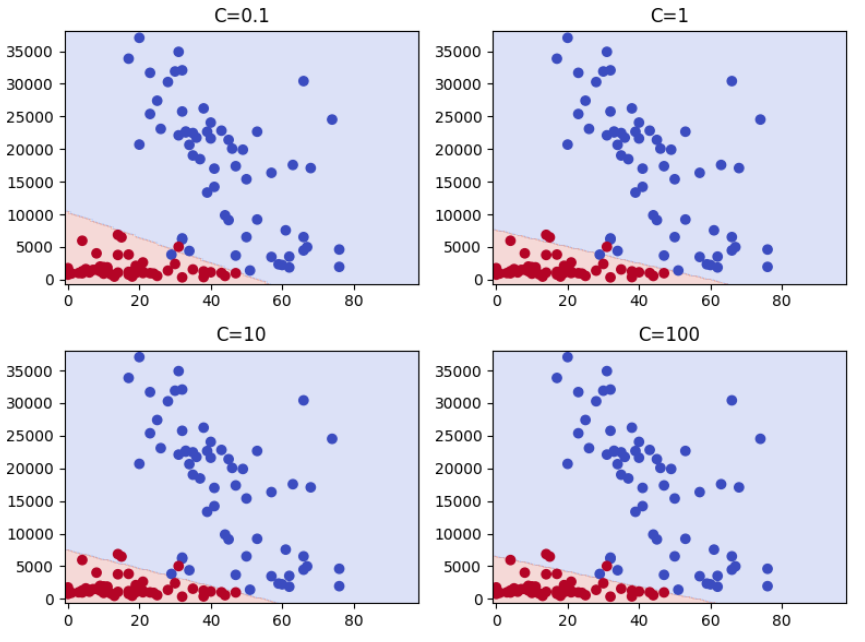
境界線の式を表示
次に決定境界の式を出力してみます。
# SVMモデルから重みベクトルとバイアスを取得
w = model.coef_[0]
b = model.intercept_[0]
# 境界線の式を表示
digits = 4 #表示する有効数字
print(f'境界線の式: {w[0]:.{digits}g}*Intensity + {w[1]:.{digits}g}*Area + {b:.{digits}g} = 0')境界線の式: -0.1135*Intensity + -0.0008943*Area + 6.795 = 0
この式が0を超えるときにクラス=0、0未満のときにクラス=1となります。
学習したモデルでの推論と結果出力
続いて、学習したモデルに以下のような新たなデータ’test_data.csv’を与えて結果を出力してみます。
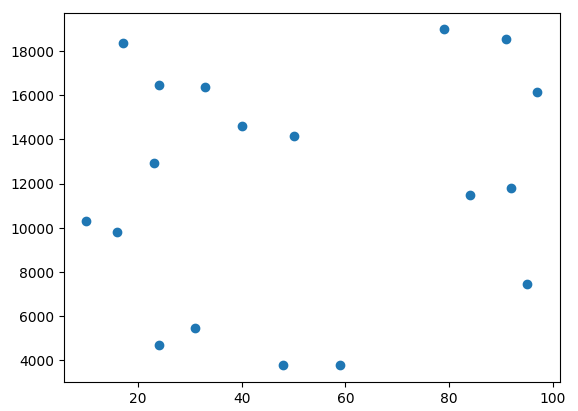

<推論するコードと結果>
# 新たなCSVファイル名
input_new_csv_filename = 'test_data.csv'
output_csv_filename = 'prediction_results.csv'
# 新たなデータフレームを作成
new_df = pd.read_csv(input_new_csv_filename, names=['Intensity', 'Area'])
# 新たなデータから推論を行う
predictions = model.predict(new_df)
# 結果を新たなデータフレームに追加
new_df['Predicted_Label'] = predictions
# 結果をCSVファイルに出力
new_df.to_csv(output_csv_filename, index=False)
print(new_df)
# xx, yyの範囲を全データの範囲に基づいて更新
combined_df = pd.concat([df[['Intensity', 'Area']], new_df[['Intensity', 'Area']]])
x_min, x_max = combined_df['Intensity'].min() - 1, combined_df['Intensity'].max() + 2
y_min, y_max = combined_df['Area'].min() - 1000, combined_df['Area'].max() + 1000
xx, yy = np.meshgrid(np.arange(x_min, x_max, 1), np.arange(y_min, y_max, 1))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# 推論結果をプロット
plt.contourf(xx, yy, Z, alpha=0.2, cmap=plt.cm.coolwarm)
plt.scatter(new_df['Intensity'], new_df['Area'], c=new_df['Predicted_Label'], cmap=plt.cm.coolwarm, edgecolors='k')
# 軸ラベルとタイトル
plt.xlabel('Intensity')
plt.ylabel('Area')
plt.title('SVM Prediction Results')
# グラフをファイルとして保存
plt.savefig('SVM_prediction_results.png', dpi=300)
plt.show()
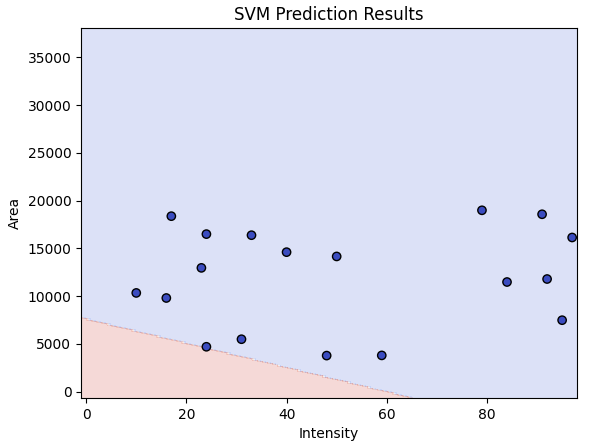
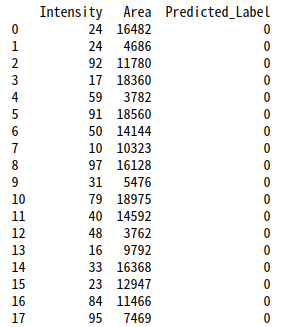
このモデルではすべてのラベルが0と分類されました。
最後に全体のコードです。
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm
import pandas as pd
# CSVファイル名
input_csv_filename = 'train_data.csv'
# データフレームを作成
df = pd.read_csv(input_csv_filename, names=['label', 'Intensity', 'Area'])
# データを取得
y = df['label']
X = df[['Intensity', 'Area']]
# 非線形SVMモデルを設定(linearカーネルを使用)
model = svm.SVC(kernel='linear', C=1)
# モデルをトレーニング
model.fit(X, y)
# 分類境界をプロット
x_min, x_max = X['Intensity'].min() - 1, X['Intensity'].max() + 2
y_min, y_max = X['Area'].min() - 1000, X['Area'].max() + 1000
xx, yy = np.meshgrid(np.arange(x_min, x_max, 1), np.arange(y_min, y_max, 1))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, alpha=0.2, cmap=plt.cm.coolwarm)
plt.scatter(X['Intensity'], X['Area'], c=y, cmap=plt.cm.coolwarm)
plt.scatter(model.support_vectors_[:, 0], model.support_vectors_[:, 1], s=100, facecolors='none', edgecolors='k') # サポートベクトルを描画
# 軸ラベルとタイトル
plt.xlabel('Intensity')
plt.ylabel('Area')
plt.title('SVM Decision Boundary')
# グラフをファイルとして保存
plt.savefig('svm_results_bector.png', dpi=300)
plt.show()
# ================= 決定境界の表示 ===================
# SVMモデルから重みベクトルとバイアスを取得
w = model.coef_[0]
b = model.intercept_[0]
# 境界線の式を表示
digits = 4 #表示する有効数字
print(f'境界線の式: {w[0]:.{digits}g}*Intensity + {w[1]:.{digits}g}*Area + {b:.{digits}g} = 0')
# ================= 推論と結果表示 ===================
# 新たなCSVファイル名
input_new_csv_filename = 'test_data.csv'
output_csv_filename = 'prediction_results.csv'
# 新たなデータフレームを作成
new_df = pd.read_csv(input_new_csv_filename, names=['Intensity', 'Area'])
# 新たなデータから推論を行う
predictions = model.predict(new_df)
# 結果を新たなデータフレームに追加
new_df['Predicted_Label'] = predictions
# 結果をCSVファイルに出力
new_df.to_csv(output_csv_filename, index=False)
print(new_df)
# xx, yyの範囲を全データの範囲に基づいて更新
combined_df = pd.concat([df[['Intensity', 'Area']], new_df[['Intensity', 'Area']]])
x_min, x_max = combined_df['Intensity'].min() - 1, combined_df['Intensity'].max() + 2
y_min, y_max = combined_df['Area'].min() - 1000, combined_df['Area'].max() + 1000
xx, yy = np.meshgrid(np.arange(x_min, x_max, 1), np.arange(y_min, y_max, 1))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# 推論結果をプロット
plt.contourf(xx, yy, Z, alpha=0.2, cmap=plt.cm.coolwarm)
plt.scatter(new_df['Intensity'], new_df['Area'], c=new_df['Predicted_Label'], cmap=plt.cm.coolwarm, edgecolors='k')
# 軸ラベルとタイトル
plt.xlabel('Intensity')
plt.ylabel('Area')
plt.title('SVM Prediction Results')
# グラフをファイルとして保存
plt.savefig('SVM_prediction_results.png', dpi=300)
plt.show()
