- scikit-learn の概要とインストール方法
- 機械学習におけるモデル手法選択のフロー
⇨ロジスティック回帰やランダムフォレストなど、たくさんある機械学習モデルの中からどの手法を選択すればいいかわからない方へ
scikit-learnを使えば、簡単に機械学習モデルの作成を行うことができます。
この記事では、scikit-learnの概要から、数ある機械学習モデルの選択方法について解説します。
scikit-learn の概要
scikit-learnはPythonで機械学習モデルを構築するための強力なライブラリです。
さまざまな機械学習タスクを実行するための豊富なツールセットが提供されています。
scikit-learnによって線形回帰、ロジスティック回帰、ランダムフォレスト、サポートベクターマシンなど、さまざまな機械学習を簡単に実行することができます。
機械学習モデルを構築する一般的な手順は以下の通りです。
- データの準備
データを読み込み、前処理や特徴量エンジニアリングを必要に応じて実施 - モデルの選択
解決しようとするタスクに応じて、機械学習モデルを選択 - モデルの訓練
fit()メソッドを使用し、選択したモデルをトレーニングデータに適合 - モデルの評価
トレーニングが完了したら、テストデータを使用してモデルの精度を確認 - モデルのチューニング
モデルのパフォーマンスを向上させるために、ハイパーパラメータを調整 - 予測の実行
predict()メソッドを使用し、未知のデータに対する予測
インストールコマンド
scikit-learnのインストールは下のコマンドで実行します。
pip install scikit-learn機械学習モデル(estimator)の選択
機械学習の問題を解決する際に最も難しい部分は適切な機械学習モデル(estimator)を選択することです。
以下のフローチャートにデータに対してどの推定器が選択するべきか大まかなガイドが示されています。
https://scikit-learn.org/stable/tutorial/machine_learning_map/
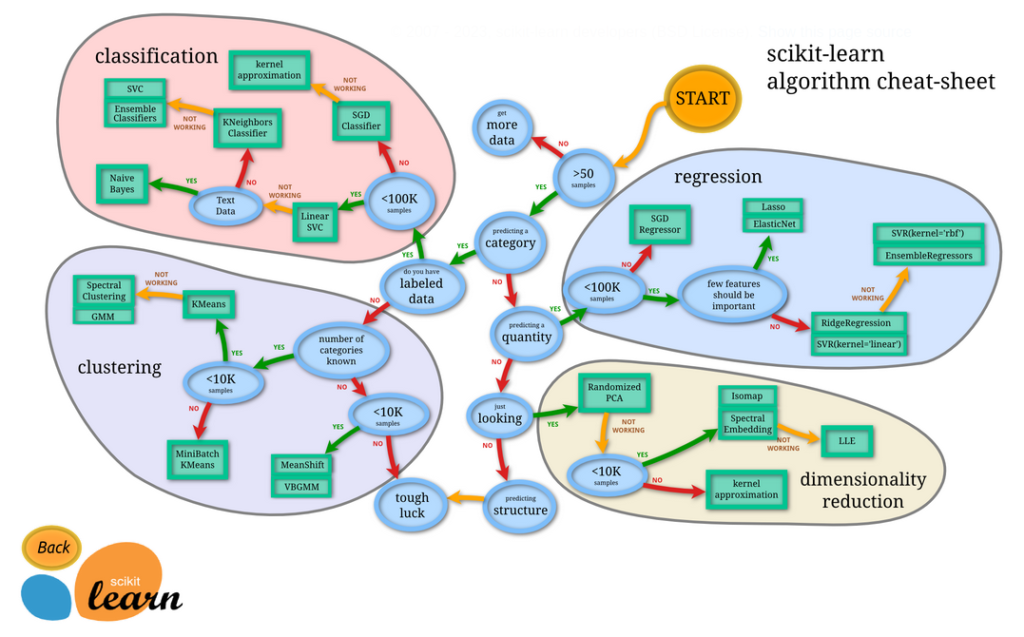
これを要約したモデル選択の大きな流れは、
- サンプル数の確認
50以下の場合はもっと集めましょう - 目的変数を確認
カテゴリ型(離散値)なのか、もしくは連続型(数値)なのか - カテゴリ型の場合
教師ラベルあり・・・分類問題(Classification)
ナイーブベイズ、サポートベクターマシン、ランダムフォレストなど
教師ラベルなし・・・クラスタリング(Clustering)
k-means、階層クラスタリング、Mean Shiftなど - 連続型の場合
回帰問題(Regression)
リッジ回帰、Lasso回帰、ElasticNet回帰、ランダムフォレストなど - その他、モデル精度を改善するためのアプローチ
次元削減(dimensionality reduction)
主成分分析(Principal Component Analysis, PCA)など
具体的な手法の選択については、サンプル数や特徴量の数によって判断していきます。
フローチャートはこれ以上の詳細な推定器の選択方法を提供していますが、上記の要約に基づいて、問題の性質とデータの特徴に応じた適切な推定器を選ぶ一助となるでしょう。

